Dans l’épisode 105 du podcast Search Off the Record, Martin Splitt et Gary Illyes, tous deux membres de l’équipe Search Relations chez Google, lèvent le voile sur le fonctionnement réel de l’infrastructure de crawl de Google. Le constat est clair : Googlebot, tel qu’on se le représente, n’existe pas.
Googlebot n’est pas un programme, c’est un client
Première révélation, et sans doute la plus importante : il n’y a pas de fichier “Googlebot.exe” que quelqu’un lance sur un serveur. Googlebot n’est ni un logiciel autonome, ni un programme monolithique.
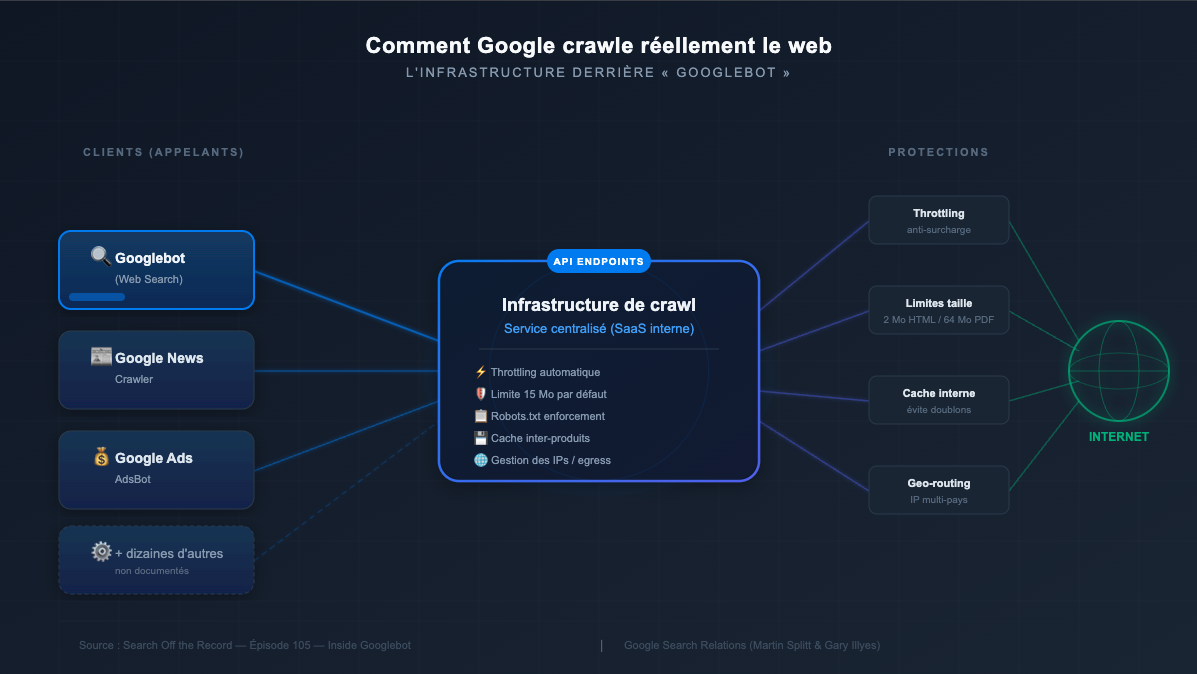
L’infrastructure de crawl de Google fonctionne en réalité comme un service interne — un “Software as a Service” (SaaS) accessible via des points d’API. Ce service centralise toutes les opérations de récupération de contenu depuis le web. Quand une équipe Google a besoin de contenu provenant d’internet, elle appelle ce service en lui transmettant des paramètres : l’URL à récupérer, le user-agent à utiliser, le délai d’attente maximum, le jeton de produit robots.txt à respecter, etc.
Googlebot n’est donc qu’un client parmi d’autres de cette infrastructure. C’est simplement le nom que l’équipe de la recherche web (Web Search) utilise pour ses propres requêtes de crawl. D’autres équipes — Google News, Google Ads, et bien d’autres — utilisent le même service avec leurs propres configurations.
Crawlers vs. Fetchers : deux modes d’opération
Gary Illyes distingue deux types d’interactions avec l’infrastructure de crawl :
Les Crawlers fonctionnent en continu, traitant un flux constant d’URLs par lots (batch). Ils opèrent de manière autonome, sans intervention humaine directe sur chaque requête. On leur confie une mission, et ils l’exécutent en arrière-plan.
Les Fetchers, eux, traitent les URLs une par une. Ils sont déclenchés par une action utilisateur : quelqu’un clique sur un bouton, et le fetcher récupère une URL spécifique. L’utilisateur attend la réponse.
Au-delà de cette distinction d’usage, les plages d’adresses IP utilisées pour les fetches sont différentes de celles des crawls, même si l’infrastructure sous-jacente reste globalement la même.
Google documente ses principaux crawlers et fetchers sur developers.google.com/crawlers, mais Gary admet que seuls les plus importants y figurent. Des dizaines, voire des centaines d’autres crawlers plus modestes restent non documentés, faute de place et de pertinence.
Un système de surveillance sophistiqué
Pour garder le contrôle sur l’ensemble de ces crawlers, l’équipe a mis en place un système d’alertes. Lorsqu’un crawler ou un fetcher dépasse un certain seuil de requêtes journalières, un ticket interne est automatiquement créé pour investigation.
Ce système a d’ailleurs permis de débusquer des situations cocasses : un crawler fantôme, associé à un projet officiellement arrêté deux ans auparavant, continuait à parcourir le web. Personne n’avait pensé à désactiver la tâche automatisée après la fermeture du projet.
La mise en cache inter-produits
Pour limiter les requêtes inutiles, Google utilise un système de cache interne agressif, indépendant des mécanismes de cache HTTP classiques. Si Google News a récupéré une page il y a dix secondes, et qu’un autre crawler (par exemple celui de Web Search) demande la même page, le système lui fournit directement la copie déjà en mémoire au lieu de retourner la chercher sur le serveur d’origine.
Attention cependant : toutes les équipes ne partagent pas forcément ce cache. Certains produits ont des politiques spécifiques qui interdisent la réutilisation de contenu récupéré par un autre service.
La question du géo-blocage
Google crawle principalement depuis les États-Unis, avec des adresses IP localisées à Mountain View, en Californie. Lorsqu’un site pratique le géo-blocage, le crawler peut se heurter à une erreur HTTP 403 ou à un timeout réseau.
Google dispose de solutions pour contourner ce problème en utilisant des adresses IP attribuées à d’autres pays, mais ces points de sortie ne sont pas conçus pour le crawl à grande échelle. Ils sont utilisés de manière ciblée, uniquement lorsque le contenu est jugé suffisamment utile pour justifier cet effort.
Le message de Gary est sans ambiguïté : il ne faut pas compter sur cette capacité. Si vous voulez que votre contenu soit crawlé de manière fiable, ne géo-bloquez pas Googlebot.
“Ne pas casser internet” : les garde-fous
L’une des raisons fondamentales de l’existence de cette infrastructure centralisée est la protection du web lui-même. Imaginez un nouvel ingénieur chez Google qui, depuis un serveur disposant d’une connexion à 10 Gbit/s, commencerait à bombarder un site de requêtes. Le site serait submergé en quelques secondes.
L’infrastructure de crawl impose des mécanismes de throttling automatiques :
- Si un site commence à ralentir (temps de connexion en hausse progressive), le crawler réduit automatiquement la cadence.
- Si le serveur renvoie une erreur 503 (Service Unavailable), le ralentissement est encore plus marqué, car cela signale une surcharge du serveur.
- Les erreurs 403 ou 404, en revanche, n’ont pas d’impact sur le rythme de crawl : ce sont de simples erreurs client (mauvaise URL, accès interdit, etc.).
Ces protections sont gérées au niveau de l’infrastructure et ne peuvent pas être outrepassées par les équipes individuelles.
La limite des 15 Mo (et ses variantes)
L’infrastructure impose une limite par défaut de 15 Mo par fichier récupéré. Au-delà, elle cesse de recevoir les octets. Mais chaque équipe peut modifier cette valeur.
Pour Google Search spécifiquement, la limite est réduite à 2 Mo pour le HTML. Pourquoi ? Parce que traiter un fichier HTML de 14 Mo (comme le standard HTML Living Standard en une seule page) serait simplement trop lourd pour le pipeline d’indexation. En revanche, les PDF bénéficient d’une limite plus élevée, autour de 64 Mo.
Ces paramètres peuvent même varier au sein d’un même produit, en fonction du contexte : une indexation urgente pourrait par exemple réduire la limite à 1 Mo pour accélérer le traitement.
Ce qu’il faut retenir
L’image mentale d’un “Googlebot” unique parcourant le web est dépassée. Voici comment il faut réellement se représenter le crawl de Google :
- L’infrastructure de crawl est un service centralisé que de nombreuses équipes internes appellent via des API.
- Googlebot n’est qu’un client de ce service — celui utilisé par l’équipe Web Search.
- La configuration est flexible : chaque requête peut avoir ses propres paramètres (limite de taille, user-agent, timeout, etc.).
- Le système protège le web avec du throttling automatique et des garde-fous intégrés.
- Le géo-blocage reste problématique : Google crawle principalement depuis les États-Unis.
- Le cache interne réduit les requêtes redondantes entre les différents produits Google.
Cette vision plus réaliste de l’infrastructure permet de mieux comprendre certains comportements observés en SEO : pourquoi les limites de taille varient, pourquoi le crawl-budget est un sujet complexe, et pourquoi le comportement de “Googlebot” peut sembler incohérent — c’est parce que derrière ce nom se cachent de nombreux clients avec des configurations différentes.
Source : Search Off the Record — Épisode 105 : Inside Googlebot, podcast de l’équipe Google Search Relations.